Entanglement Boosting: Hardware-Efficient Logical Interconnects

The full paper is available at: https://arxiv.org/abs/2511.10729
The Scaling Challenge
To reach the large physical qubit count required for utility-scale applications, e.g. one million qubits, current quantum computing platforms face significant technical challenges in scaling within a single processor. While significant qubit count increase is planned, maintaining operational capabilities while significantly scaling up a single monolithic device is a big challenge due to many practical [1] and fundamental reasons [2]. Therefore, whether the increased qubit-count in monolithic devices means the equally increased logical-level computing capability, remains open.
While modular scaling by connecting multiple high-quality quantum processing units (QPUs) offers a clear path forward for sustained growth of logical-level computational capability, this distributed approach also faces a critical hurdle: the interconnect overhead. Without efficient links, the interface between modules can become a massive drain on local resources, potentially negating the very advantages of modular scaling.
At NanoQT, our mission is to resolve this bottleneck through building high-performance cavity-assisted interconnect hardware and developing the underlying protocols and architectural mechanisms that minimize resource overhead– such as qubit counts, entanglement consumption, and computation time. This strategy builds upon our scalable distributed quantum computing architecture [3], with our most recent breakthrough in entanglement boosting—highlighted in this post—providing the critical implementation path [4].
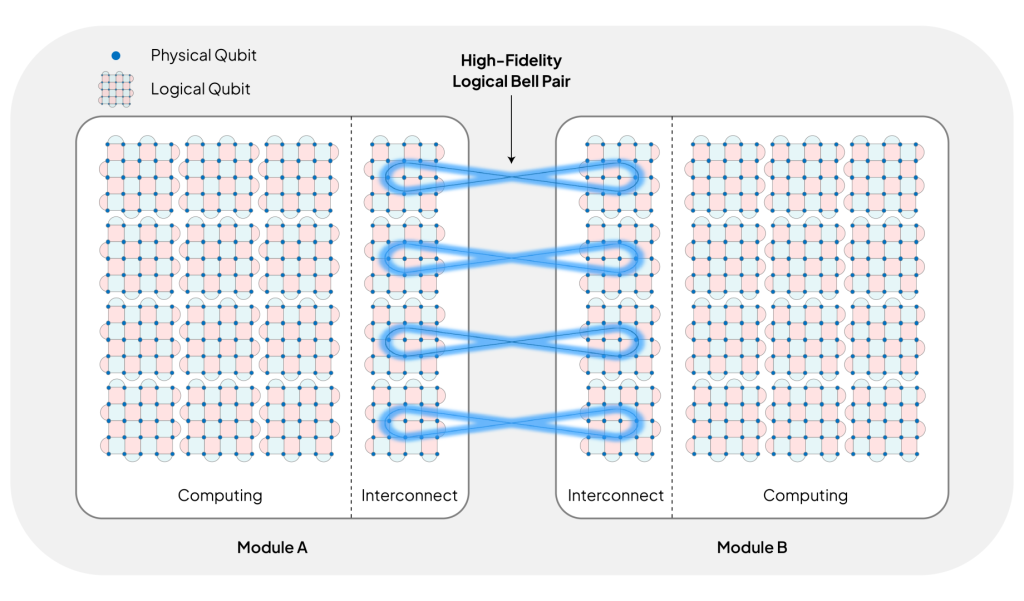
The Cost of Networking: Remote Bell pairs
In a distributed architecture, separate QPUs must work together as a single cohesive machine. The essential ingredient for this coordination is the remote Bell pair—a shared entanglement between two distant modules. These Bell pairs allow us to perform remote CNOT gates, the fundamental operations that enable a qubit in one module to interact with a qubit in another.
While recent experimental demonstrations of remote CNOT gates using trapped ions have shown promise, they currently suffer from low operation rates (~100 Hz) and high error rates in the few-percent range [5]. These errors exceed those of high-performance local gates by at least an order of magnitude, creating a significant bottleneck for modular scaling. To reach utility-scale performance, we must move beyond these noisy physical links and transition to logical-layer abstraction.
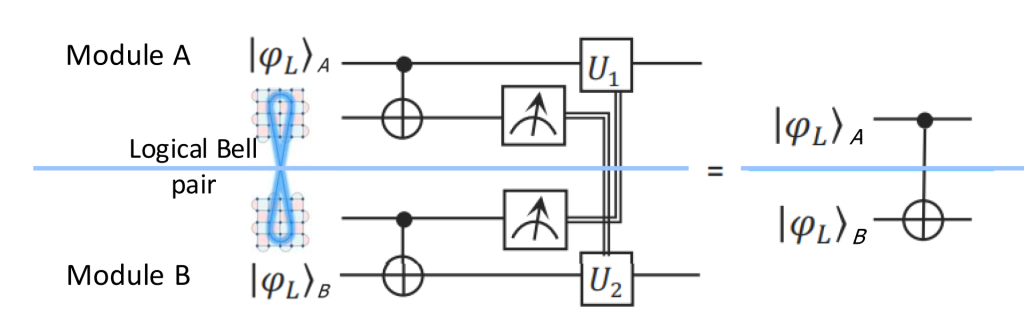
Executing quantum algorithms at utility scale requires fault-tolerant primitives, such as logical CNOT gates capable of operating across both local and remote domains. The architecture for a logical remote CNOT relies on the generation of a logical Bell pair—a high-fidelity, error-corrected entanglement resource shared between logical nodes—which we then use as the “resource” to execute the remote gate. The central challenge now is how to efficiently generate these high-fidelity logical Bell pairs from the noisy physical Bell pairs provided by the network.
The Scaling Bottleneck: A Costly Trade-off
Bridging the performance gap between 1% physical error rates and the 10-12 logical error rates required for utility-scale fault-tolerant computation is a formidable task. Despite the rapid progress, this has forced a difficult trade-off between network efficiency and local QPU capacity:
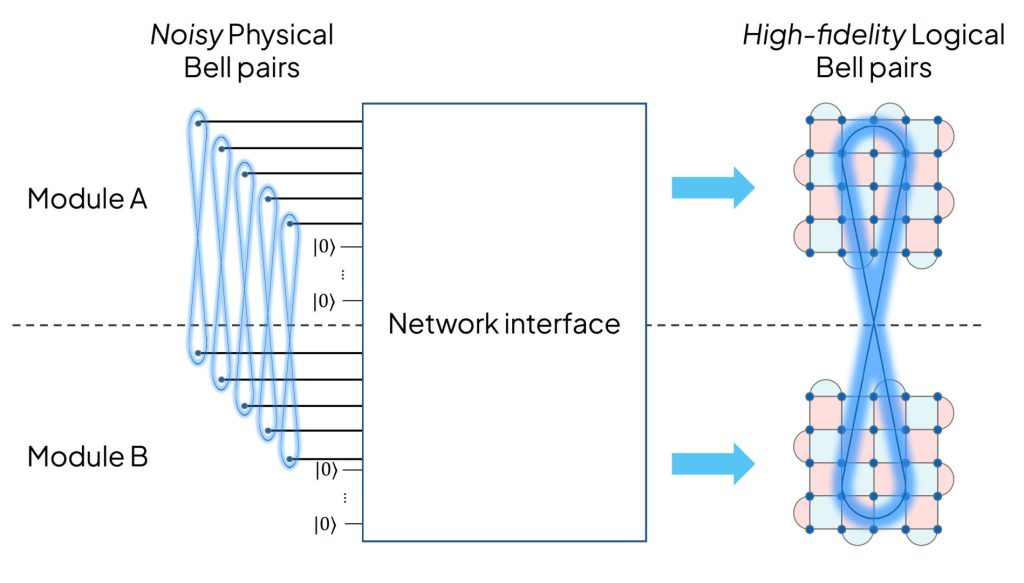
- The Physical-to-Logical Approach: This method prioritizes simpler local operations but is extremely demanding of entanglement [6, 7]. To brute-force the transition to 10-12, it can require over 1,000 physical Bell pairs to build just one logical link.
- The Injection-and-Distillation Approach: This method saves network traffic by “injecting” noisy pairs and distilling them locally [8]. However, the local processing is intensive, requiring upwards of 1,000,000 local qubit-cycles for a single high-fidelity pair.
Our Solution: Entanglement Boosting, Efficiency by Design
In our latest work, we introduce Entanglement Boosting, a network-interface protocol that achieves the “best of both worlds” [4]. By employing a strategic three-stage process, we transform physical remote entanglement into logical Bell pairs with error probabilities as low as one-in-a-trillion:
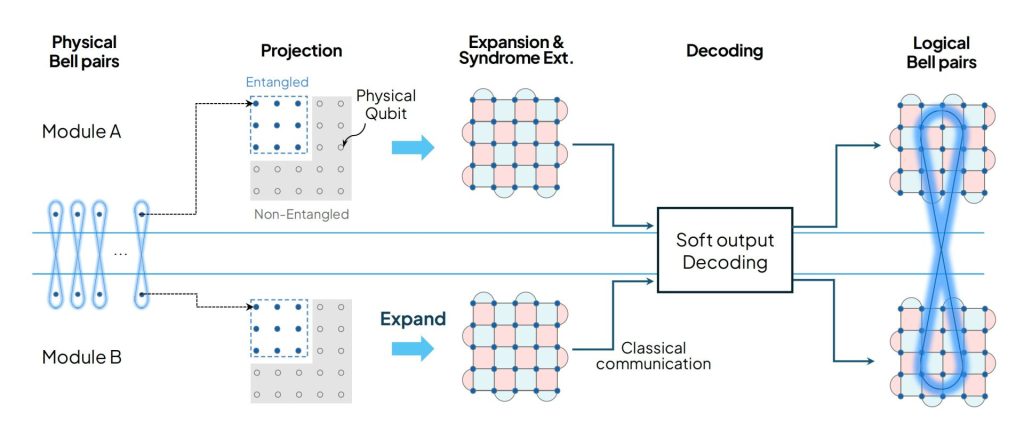
- Logical Code Projection: We first project noisy physical Bell pairs into a moderate-sized logical code block. Crucially, we only entangle a strategic subset of qubits, avoiding the massive rate loss associated with projecting directly into large-distance codes.
- Code Expansion & Syndrome Extraction: We then expand the code to its target distance while performing syndrome extraction to detect errors without destroying the underlying quantum information.
- Soft-Information Decoding: Finally, we apply a high-precision filter using “soft” decoding. Unlike conventional “hard” decoding, soft-information uses confidence scores for every measurement, allowing us to build the logical link only from high-certainty data. This improves the logical error rate by multiple orders of magnitude while only discarding a marginal fraction of attempts.
The Impact by the Numbers
To reach a target error rate of 10-12—the threshold required for practical fault-tolerant computing applications—our protocol delivers a decisive leap in hardware efficiency:

Our method eliminates the trade-off between network traffic and local compute, providing a balanced, low-overhead path to scaling. As the data shows, Entanglement Boosting requires only 1/10th the network usage of state-of-the-art physical-to-logical approaches. More importantly, it achieves this without the massive “local resource drain” that makes distillation-heavy methods impractical for compact modules. For instance, in a neutral atom platform with a typical cycle of 1 ms, generating a single logical Bell pair requires ~ 100 physical Bell pairs. This necessitates a physical generation rate of 100 kHz—a target that, while adding minimal overhead to the local QPU, still demands a three-order-of-magnitude improvement in generation rate over the current state of the art.
Outlook: Towards Scalable Quantum Interconnects
This work constitutes a key component of the distributed FTQC architecture proposed in [3], serving as the vital link between high-performance physical protocols [9, 10] and system-wide fault-tolerant frameworks [11, 12]. Our nanofiber-cavity interconnects are engineered to deliver physical Bell pairs at high rates with error rates safely below 1%. By leveraging this high-performance regime, our entanglement boosting protocol transforms raw physical speed into high-bandwidth logical interconnects with minimal overhead.
Looking forward, we anticipate further throughput gains by integrating system-level optimizations such as soft-information decoding, leveraging photon detection timing, and correlated decoding for transversal-gate protocols. Ultimately, this synergy between high-rate cavity-QED hardware and sophisticated decoding strategies establishes our architecture as the new standard for scalable, distributed quantum computing.
References
[1] Manetsch et al., Nature 647, 60–67 (2025).
[2] M. Saffman, arXiv:2505.11218 (2025).
[3] Sunami et al., PRX Quantum 6, 010101 (2025). (Blog page)
[4] Sunami et al., arXiv:2511.10729 (2025).
[5] D. Main et al., Nature 638, 383–388 (2025).
[6] Ramette et al., npj Quantum Information 10, 58 (2024).
[7] Maeda et al., arXiv:2503.14894 (2025).
[8] Pattison et al., arXiv:2408.15936 (2024).
[9] Kikura et al., PRX Quantum 6, 040351 (2025). (Blog Page)
[10] Kikura et al., arXiv:2507.01229 (2025). (Blog Page)


