Unlocking Both FTQC Speed and Scalability in Neutral Atom Systems with New Transversal Surface-Code Architecture
The full paper is available at: https://www.arxiv.org/abs/2506.18979
Introduction
While NanoQT is often recognized as a hardware company, our mission goes beyond component delivery. We are committed to delivering system-level performance—not only by building core quantum hardware, but by shaping the architecture needed to realize scalable, fault-tolerant quantum computing (FTQC).
This belief is grounded in the fact that quantum performance depends not only on the quality of individual qubits, but on the architecture used to execute quantum computation. This is especially true for FTQC, where system-level design and resource orchestration ultimately define performance and scalability.
While superconducting circuits benefit from mature architectural frameworks, the equivalent for neutral atom systems is still emerging. Yet neutral atoms offer unique advantages, such as all-to-all connectivity and access to transversal gates, thanks to dynamic reconfigurability, not readily available in superconducting platforms.
Neutral atom qubits are often perceived as slower than other modalities, due to longer gate durations, atom transport latency, and slower readout. However, by leveraging the intrinsic flexibility of neutral atom hardware at the system level, NanoQT demonstrates that it’s possible to build FTQC architectures capable of executing large-scale universal FTQC at speeds comparable to those of well-established baseline for superconducting systems operating lattice surgery.
Furthermore, this design solves the fundamental open problem of existing neutral-atom architectures with regards to the compatibility with celebrated threshold theorem, a fundamental requirement to scale FTQC. This work is a clear example of how architectural design can compensate for the physical limitations of a quantum system.
Challenge
At the heart of scalable FTQC lies a fundamental battle against time: because quantum states decohere and noise accumulates over time, speed is critical. This is the essence of the threshold theorem, which states that errors must be corrected frequently enough to remain below a threshold. In practice, this requires rapid and repeated syndrome extraction—the process of detecting and correcting errors—through gate operations and measurements.
Two conventional architectural strategies have been explored to meet this demand:
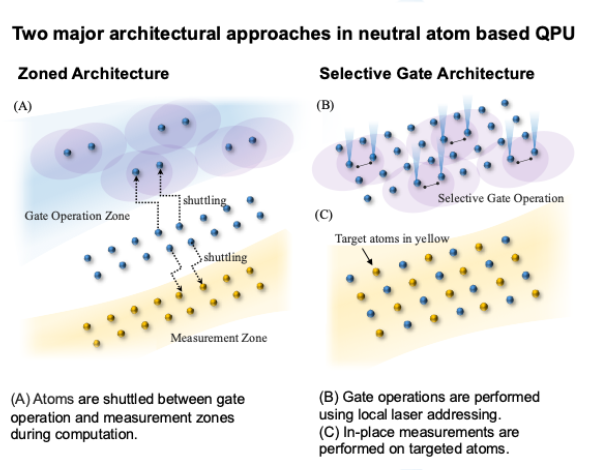
A. Zoned Architecture:
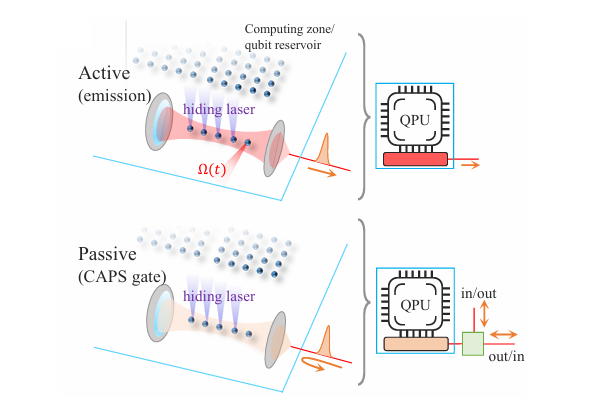
In this approach, the quantum processor is partitioned into specialized regions or “zones” for operations like gates and measurements [1]. Atoms are shuttled between these zones during computation (Fig. A). While this design supports transversal gates, which act on multiple qubits simultaneously, it also introduces shuttling overhead for every low-level operation, leading to time delays and decoherence. These effects worsen as system size scales: with more qubits, the transport distance grows, leading to longer transport times before arrival at the measurement zone and increased accumulated errors.
B. Selective Gate Architecture:
Here, gate operations are performed using local laser addressing, eliminating the need for atom shuttling (Fig. B) [2]. Measurements can also be done in place, without moving atoms to separate zones (Fig. C). This shuttling-free approach avoids the constraints of zoned architectures, reducing both latency and decoherence. However, it sacrifices transversal gates, which are essential for fast, parallel operations, ultimately resembling a slower version of superconducting-qubit systems.
In summary, both architectures involve a fundamental trade-off:
- Zoned architecture enables transversal gates but suffers from shuttling overhead at every level.
- Selective gate architecture allows local operations without shuttling, but sacrifices the advantages of transversal gates and fails to fully leverage the strengths of neutral atom systems.
This trade-off has limited the development of scalable, high-speed FTQC on neutral atom platforms. What is needed is an architecture that preserves transversal gate capability without incurring shuttling overhead—combining the best of both approaches.
Our solution
We propose new architecture optimized for neutral atom systems, addressing the limitations of both zoned and selective gate architecture by enabling transversal gates and constant-time error correction independent of system size. Inspired by game-based frameworks originally designed for superconducting qubits [3], we adopt the surface code to enable direct performance benchmarking with superconducting platforms, where it is the industry standard for FTQC.
In our architecture, each surface-code cell transitions between modes—idle, gate, or measurement—following simple local rules. Crucially, the shuttling-free syndrome extraction using atom-selective gates and local readout enables error correction, both between and during logical gate execution. Syndrome extraction runs in constant time, regardless of code distance, allowing correction cycles to meet the threshold theorem.
We also integrate pipelined resource-state factory design applicable, for example, for magic-state distillation, using transversal gates to reduce space-time overhead and support scalable FTQC.
Despite 100× slower gate speeds than those of the superconducting circuits, our proposed architecture completes a benchmark computation—100 logical qubits, 10⁸ T counts using ~76,000 physical qubits—in 3.4 hours, matching the performance of well-known baseline superconducting qubit platform in ~2 hours at a similar qubit count [3]. This is enabled by our architecture’s emphasis on system-level efficiency over raw gate speed.
This architecture is well suited to ytterbium atoms, the species adopted by NanoQT, due to the accessibility of long-lived metastable states and the ability to perform selective operations.
Next step
This work marks a key milestone in demonstrating the power of architectural design in neutral atom systems—but our optimization toolkit is just getting started.
In the next phase, we plan to explore high-rate quantum error-correction codes such as quantum LDPC and concatenated codes, which offer excellent overhead efficiency and are well suited to neutral atom platforms. In parallel, we aim to unlock the full potential of multi-module architectures, made possible by our nanofiber-cavity based fast quantum interconnect.
These untapped levers hold significant promises for further gains in speed, scalability, and resource efficiency, and represent core focus areas on our roadmap ahead.
Reference:
[1] D. Bluvstein et al., Nature 626, 58 (2024).